Zientzia eta Teknologiaren Corpusa
Diseinua eta metodologia
- 1 Sarrera
- 2 Corpus berezia edo espezializatua
- 3 Corpusgintza-eredua
- 4 Diseinua: ZT corpusaren ezaugarriak
- 5 Cospusgintza-lana
- 6 Ondorioak
- 7 Bibliografia
1 Sarrera
Corpusak azken urteotan hizkuntza-baliabide gisa hartu duen garrantzia inork gutxik uka lezake gaur egun. Corpusa hizkuntza aztertzeko ezinbesteko baliabidea da, hainbat alorretan erabiltzen dena: lexikografian, sintaxian, semantikan, diskurtsoaren analisian... Adibidez, gaur egun, mundu zabalean egiten diren lexikografia-lanetan hutsik egin gabe aipatzen den hitza corpus da. Dela hiztegigintzaren osagarri, dela hiztegia bera egiteko lehengai eta abiapuntu, corpusa hiztegigilearen tresna eta euskarri ezinbestekotzat jotzen da gero eta maizago, hainbesteraino, non corpusean oinarritua edo, gutxienez, corpusaren laguntzaz taxutua ez den hiztegiari nekez aitortzen baitzaio zehaztasuna, zorroztasuna, fidagarritasuna eta, oro har, kalitatea. Esan gabe doa, corpusak ez dira lexikografian soilik erabiltzen, diziplina oso bat da corpus-hizkuntzalaritza. Corpusek datu linguistikoak jasotzen dituzte eta baliozko lanabesak dira hizkuntzaren erabilera erreala aztertu nahi bada. Urte askoan, horrelako azterketa enpirikoak egitea hizkuntzalaritzaren korronte nagusitik kanpo egon bada ere, azken urteotan gero eta tresna estimatuagoak dira, ez noski gramatika sortzailearen alternatiba edo aurkari gisa, beste ikuspegi baten eta ebidentzien ekarle gisa baizik. Gainera, corpusetan bildutako datu-kopuru handien bidez, hizkuntza-teknologien alorreko behar eta eginkizun batzuei beste era batera erantzuteko modua egoten da (prozedura estatistikoetan oinarritutako desanbiguazio-teknikak, itzulpen-memoriak, etab.).
Berez, edozein testu-bilduma har liteke corpustzat; hala ere, gaur egun baldintza batzuk ezarri ohi dira testu-bilduma bat corpustzat jotzeko: hizkuntza-erakusgarri 'errealen' multzo 'handia' izatea, irizpide batzuen arabera bildua, formatu elektronikoan biltegiratua eta informazio linguistikoz hornitua (Bach et al. 1997: 4). Baldintza horien guztien helburua, azken buruan, corpusa hizkuntza-baliabide eraginkorra izatea da, hau da, corpusetik datu linguistiko asko, aberatsak eta esanguratsuak lortzeko aukera izatea.
Hasierara2 Corpus berezia edo espezializatua
2.1 Zer da corpus berezia?
Corpus berezia edo espezializatua (special corpus edo specialized corpus) hizkuntzaren erabilera-eremu espezifiko bateko edo hizkuntza-aldaera jakin bateko testuak biltzen dituen corpus-mota da, eremu edo aldaera horretako ezaugarriak aztertzeko asmoz eratua (Sinclair 1996: 10). Corpusaren helburua hizkuntzaren erabilera-eremu guztietarako baliagarria edo 'adierazgarria' izatea denean, 'erreferentzia-corpusa' edo 'orotariko corpusa' dela esan ohi da ( Sinclair 2002: 10; Leech 2002: 1).
2.2 Zergatik behar dugu corpus berezi bat zientzia eta teknologiaren alorrean?
Badira hogeita hamar urte baino gehiago euskara zientzia- eta teknologia-gaietan erabiltzen hasi zela. Geroztik egindako lanaz eta, bereziki, handik hona argitaratu diren lanez, iritzi desberdinak daudela esan daiteke; mutur banatan, honako hauek: batzuentzat aintzat hartzekoa dena, 'tradizio berria' dena, baztergarritzat edo ez ikusia egiteko modukotzat dute beste batzuek. Ez gaude ados azken urteotako testu-produkzio horren deskalifikazio orokorrarekin eta baztertzeko joerarekin, ezta ezinbestean segitu beharreko eredua finkatu delako ustearekin ere; hau da, uste dugu jarrerak 'kritikoa' izan behar duela. Gure iritzia da testu-produkzio hori aztergaitzat hartu behar litzatekeela, eta, horretarako, corpusa behar dela.
Euskaraz azken urteetan eratu diren corpus lematizatuak 'orotarikoak' dira (XX. mendeko euskararen corpus estatistikoa; Urkia 2002: 6), edo, Ereduzko Prosa gaur zein Ibinagabeitia Proiektua-ren kasuan, literatura edota prentsa jasotzen dituzte. Lematizatu gabeko corpusak ere badaude (OEHko Testu-corpusa, Klasikoen Gordailua...).
Zientzia eta teknologian erabiltzen den euskara aztertzeko, alor horietako testuak biltzen dituen corpusa erabiltzea litzateke zentzuzkoena. Hau da, behar berezi horri erantzuteko, egokiena baliabide 'berezi' bat eratzea delakoan gaude, hartarako berariazkoa hain zuzen ere. Asmo horri 'corpus berezia' dagokio. Behar horri erantzuteko asmoz sortu dugu Zientzia eta Teknologiaren Corpusa (aurrerantzean, ZT corpusa).
2.3 Zertarako erabil dezakegu corpus berezia?
Corpus berezien bidez, erabilera-eremu espezifiko baten edo aldaera jakin baten hizkuntza-ezaugarriak hobeto aztertzeko aukera dago. Horrekin batera, espezialitate-arloetako hizkuntza-erabileraren eta erabilera arrunt edo orokorraren arteko aldeak ere azter daitezke. Aztergaiak hizkuntzaren aztertze-eremu askotakoak izan daitezke: lexikoa, terminologia, fraseologia, morfosintaxia, semantika, pragmatika, diskurtsoa, estilistika, testugintza... (Bowker et al., 2002: 31-39). Hona hemen batzuk:
- Terminologia, lexiko espezializatua: terminologia-azterketak, terminoen erauzketa erdiautomatikoa, termino-aldaeren azterketa eta tratamendua, neologismoen detekzioa
- Fraseologia-unitate espezializatuen azterketa
- Diskurtso espezializatuaren azterketa (hitz-ordena, gramatika-egiturak, joskera, estiloa, testu-egitura...)
- Kontzeptu-mailako informazioaren erauzketa, ontologiak eratzeko teknikak
- Testu-sailkapen automatikoa
Aztertze-eremu horiek hainbat aplikazio-eremutan izan daitezke baliagarri:
- Terminologiaren normalizazioa
- Hiztegigintza espezializatua (hiztegi terminologikoak eta teknikoak)
- Hiztegi orokorretan sartzekoak diren termino espezializatuen hautaketa
- Hitz-adieren desanbiguazioa
- Informazioaren berreskurapen eta erauzketa
- Xede berezietarako hizkuntza-irakaskuntza (curriculuma, syllabus-ak)
Corpuseko datuak aztertuz, hizkuntzaren aztertzaileek (hizkuntzalariek, euskara-teknikariek, irakasleek...) ondorioak atera ditzakete eta proposamenak egin ere bai, dagokion alorreko adituek hizkuntza-ereduari buruzko argibideak edo 'gidalerroak' izan ditzaten, eta erakunde arau-emaileek ere espezialitate-alorreko ebazpenak eman ahal izan ditzaten. Beraz, gure ikuspegia ez da eredu-emaile izatea, ez ditugu corpuserako obrak 'kalitate-irizpide' baten arabera bahetuko. Proiektu honen helburua ez da zientzia eta teknologiaren alorreko 'ereduzko corpusa' eratzea. Aitzitik, inoiz 'eredutzat' har litekeen ikuspegi edo baliabide bat moldatu ahal izateko lehen urrastzat jotzen dugu gure proiektua.
Goian esan dugu hizkuntza-erabilera espezializatuaren ezaugarriak 'hobeto' aztertzeko eta ezagutzeko aukera eskaintzen dutela corpus espezializatuek. Zergatik esan dugu hori? Bistan dena, aztertze-helburu jakin batekin diseinatu eta eratu den corpus espezializatuan, helburu horrekiko errelebanteak diren fenomenoei gertuagotik begiratzeko aukera dago, aztertu nahi dugun hizkuntza-erabileraren lagin- eta ebidentzia-dentsitate handiagoa egoteko aukera dagoelako. Corpusa gure interesekoa den alorreko hizkuntza-erabileraren adierazgarri izatea da horretarako ezinbesteko baldintza. Baldintza hori betetzen bada, hizkuntza-erabilera edo aldaera horretaz eskura ditzakegun datuak doiagoak eta aberatsagoak dira corpus orokor batetik eskura ditzakegunak baino. Horrexetan dago corpus espezializatuen baliagarritasunaren gakoa.
Hasierara3 Corpusgintza-eredua
Corpusa nolanahi bildutako testu-multzo hutsa izango ez bada, corpusgintza gidatuko eta egituratuko duen eredu bat da beharrezkoa. Corpusgintzan lau urrats nagusi bereizi ohi dira:
- Diseinua: corpusaren helburuak eta ezaugarriak zein izango diren, testuak zein irizpideren arabera corpuseratuko diren, testuak zein mailatan eta nola prozesatuko eta etiketatuko diren...
- Corpus gordina eratzea: corpuseratzekoak diren testuak eskuratzea eta corpuserako hautatu den formatura bihurtzea
- Etiketatzea: corpusa osatzen duten testuei buruzko informazioa (metadatuak), egitura, formatu-ezaugarriak, informazio linguistikoa (lema, kategoria...)
- Corpusak analizatzeko eta ustiatzeko tresnak: corpusaren kontsulta diseinatzea eta inplementatzea
Hurrengo ataletan, eredu horren araberako corpusgintza-prozesua azalduko dugu.
Hasierara4 Diseinua: ZT corpusaren ezaugarriak
ZT corpusaren proiektuak hau lortzea du helburutzat:
Zientzia eta Teknologiaren alorreko testu-bilduma egituratua, alorreko testu-produkzioaren eta -izaeraren adierazgarri izateko asmoz eratua, eta egitura aldetik eta linguistikoki etiketatua, gaur egungo estandarren arabera.
Gainera, hona hemen proiektuaren ezaugarri giltzarri batzuk:
- Eremuari edo 'jakintza-alorrari' dagokiola, proiektu honen helburua ez da espezialitate-arlo guztiak kontuan hartzea; espezialitate-hizkeren ikuspegitik, beraz, gure helburua murritza da nolabait: Zientzia eta Teknologiaren alorreko testuak corpuseratzea
- Generoari edo 'testu-motari' dagokiola, zabal jokatu dugu. Zenbait testu-mota eta komunikazio-erregistro hartu ditugu
kontuan; horiek guztiak bi mota nagusitara bil daitezke:
- adituen arteko komunikazioa (artikulu teknikoak, tesiak…)
- adituen eta ez-adituen arteko komunikazioa (testu-liburuak, eskuliburuak, dibulgazioa, erreportajeak…)
- Baliabide linguistikoa eratu nahi dugu, ez dokumentala. Horren ondorioz, ezinbestekoa da corpusa linguistikoki prozesatzea eta etiketatzea (ikusiko dugu zein izango den gure konpromisoa); bestetik, ez da beharrezkoa jatorrizko dokumentuaren formatu- eta maketa-ezaugarri guztiak etiketatzea, ezta elementu grafikoak ere, baina bai oinarrizko testu-egitura eta linguistikoki interesgarriak izan daitezkeen formatu-ezaugarri batzuk (letra-tipoaren aldaketa, letra-estiloa, komatxoak…) eta horien balio desanbiguatuak (aipuak diren, edo nabarmentze hutsak, atzerri-hitzak, metahizkuntza, terminoak…). Bestetik, baliabide berrerabilgarria eta eramangarria izan behar luke, eta, horretarako, testuak kodetzeko eredu estandarren araberakoa
- Gure ikuspegia ez da eredu-emaile izatea. Proiektu honen helburua ez da zientzia eta teknologiaren alorreko 'ereduzko corpusa' eratzea. Aitzitik, inoiz 'eredutzat' har litekeen ikuspegi edo baliabide bat moldatu ahal izateko lehen urrastzat jotzen dugu gure proiektua
- Euskarria: testu idatziak eta argitaratuak soilik corpuseratuko dira, corpusaren aldi honetan behinik behin; jakitun gara horrek kanpoan uzten dituela ahozko komunikazioaren alderdia. Hala ere, gaur egun proiektu honen ahalmenetik at daude zientzia eta teknologiaren alorreko ahozko komunikazioaren laginak corpuseratzeko beharrezkoak diren tresnak eta baliabideak
- Itzulpenak: jatorriz euskarazkoak diren obrez gain, euskarara itzulitakoak ere cospuseratzea erabaki dugu
- ZT corpusaren diseinuari buruzko informazio zehatza nahi izanez gero, Mendebalde Kultur Alkartearen Euskera zientifiko-teknikoa IX. Jardunaldietan argitaratutako Zientzia eta Teknologiaren corpusa artikulura jo dezakezu. Hurrengo lerroetan, alderdi nagusiak labur azalduko ditugu.
Irudi honek argi adierazten du ZT corpusaren esparrua zein den:
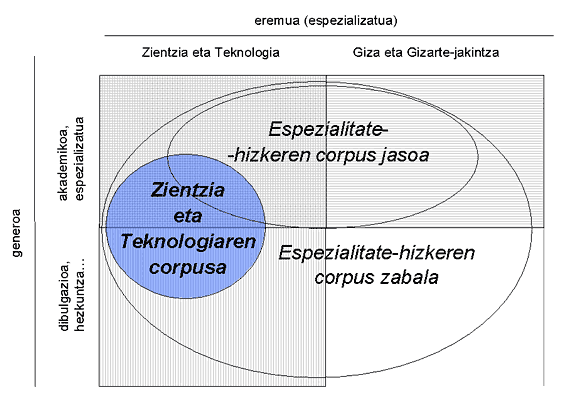
1. irudia. ZT corpusaren esparrua: eremua eta generoa.
ZT corpusean, euskaraz 1990-2002 bitartean argitaratu diren zientzia eta teknologiaren alorreko obrak jaso nahi ditugu. Bi datak bat datoz, hurrenez hurren, Euskaltzaindiaren araugintza berriaren hasierarekin, eta proiektu honen hasierarekin berarekin. Corpusa bi ataletan antolatuta dago. Batetik, adierazgarria izateko asmotan diseinatu den gune orekatua; bestetik, eskuragarritasunaren arabera corpuseratzen diren obrez edo obra-zatiez osatutako atal irekia. Hain zuzen ere, gune orekatuan ez dira obra osoak sartzen, obren lagin etenak baizik. Horrek berekin dakar gune orekaturako aukeratu den obra baten pasarte ez hautatuak (lagin eten horien artekoak), eskura izanez gero, corpusaren atal irekian sar daitezkeela (gune orekaturako hautatu ez diren baina eskura dauden obrekin batera). Gune orekatuan zein obra sartu behar den eta obra bakoitzetik zein testu-masa eta zein pasarte sartuko diren ere erabaki egin behar da. Horretarako, lehenik 1990-2002 bitarteko zientzia eta teknologiaren alorreko obren inbentarioa egin dugu. Hurrena, adierazgarritasuna edo 'oreka' bermatuko duen lagintze-eredu estatistikoa landu dugu. Eredu horren lehen oinarria da laginketa geruzatua izatea, eta geruzak sortzeko erabili ditugun parametroak 'Eremua' eta 'Generoa' dira. Jakintza-arloak 'Eremua' parametroaren arabera sailkatu ditugu, eta testu-motak 'Generoa' parametroaren arabera:
- Eremua
- Zientzia zehatzak (Matematika eta Logika)
- Materiaren eta energiaren zientziak (Fisika eta Kimika)
- Lurraren zientziak (Geologia, Ozeanografia, Geografia...)
- Biziaren zientziak (Biologia, Medikuntza, Ingurumena...)
- Teknologia (Teknologia Mekanikoa, Teknologia Elektrikoa/Elektronikoa, Telekomunikazioak, Informatika, Aeronautika...)
- Bestelakoak (Ekonomia, Arte-teknologiak, Antropologia...) 1
- Orokorra
- Generoa
- Oinarrizko hezkuntzako materiala
- Goi-mailako liburua (espezialistentzako liburua + goi-mailako hezkuntzako liburua)
- Artikulu espezializatua
- Dibulgazio-artikulua
- Dibulgazio-liburua
- Administrazio publikoko dokumentua
Geruza edo 'sail' bakoitzean eremu-genero konbinazio bakoitzeko obrak daude, eta laginketaren ausazkotasuna geruza horietako bakoitzean bermatzen da. Horrela jokatuz, ziurta dezakegu mota guztietako obrak ordezkaturik egongo direla gune orekatuan. Bigarren oinarria da geruza bakoitzaren tamaina, hasiera batean behintzat, geruzak populazioan duen proportzioaren araberakoa izatea; inbentarioa amaitutakoan, zenbait doikuntza txiki egin dira, geruza edo sail batzuen proportzio handiak txikiagotzearren. Landu den lagintze-eredu estatistikoan, honako hauek ere automatikoki zehazten dira: a) geruza bakoitzetik zenbat obra hartu behar diren; b) obra bakoitzetik zenbat hitz hartu behar diren (obraren tamainaren arabera); c) obra bakoitzetik lagin etenak hartzea (automatikoki egiten da XML dokumentuan). Lagin-tamaina minimoa 300 hitz da.
Gune orekatuan zenbat hitz sartu behar liratekeen kalkulatzerakoan, kontuan hartu ditugu, batetik, inbentarioko datuak aztertuz zenbatetsi den hitz-kopurua (98 milioi hitz), eta, bestetik, euskarazko bi corpus txikiren forma/lema erlazioaren azterketa eta estrapolazioak aurreikusarazi digun corpus-tamainaren eta lema-kopuruaren arteko erlazioa. Horiek horrela, 5 milioi hitzeko gune orekatua diseinatu da (gune orekatuaren tamaina).
Gune orekatuan biltzen diren laginak automatikoki prozesatu ez ezik, eskuz ere berrikusten dira, corpusgintzaren urrats bakoitzean egiten diren lanak zuzentzeko edo desanbiguatzeko. Atal irekia, berriz, automatikoki baino ez da prozesatzen. Dena den, etiketatze linguistikoan, atal irekiko testua halako masa handi bat eskuz landu ondoren prozesatzen da, eskuz egindako lanetik 'ikas' dezan, eta asmatze-tasa handiagoa izan dadin.
Hasierara5 Cospusgintza-lana
Corpusgintza-ereduko urratsak modu sistematiko eta egituratuan egiteko, corpus-metodologia bat landu behar da, eta, hori inplementatzeko, corpusgintza-tresna bat. Lehendik garatutako tresnak eta proiektu honetarako garatuak integratuz, Corpusgile aplikazioa sortu dugu. Corpus gordina eratzea eta etiketatze-lanak dira kudeatu behar dituen prozesu giltzarriak. Batetik, IXA taldeak euskara automatikoki prozesatzeko garatutako tresna batzuk (Eustagger , Eulia) moldatu eta areago garatu ditugu, eta, horrekin batera, corpusgintza bera kudeatzeko eta, oro har, corpus-lanak egiteko beharrezkoak diren tresnak ere garatu behar izan ditugu. Kontuan hartu behar da merkaturatu diren corpusgintza-tresna urriek ez dutela euskararen prozesamendu automatikorako beharrezkoak diren tresnak eta baliabideak integratzen, eta ez direla egokiak euskarazko testu-corpusak eratzeko. Halaber, Corpusgile-ren bidez corpusgintzaren etorkizuneko helburua den erreferentzia-corpus orokorra egiteko baliagarria izango den metodologia adostua eta kontrastatua eskaini nahi izan dugu.
Corpusgile hiru moduluz osatua da:
- TB: testu-bilketaren modulua (corpus gordina biltzeko modulua)
- EE: egitura-etiketatzea egiteko modulua
- EL: etiketatze linguistikoa egiteko modulua
Diagrama honetan bildu ditugu urrats horien eta horien barneko prozesu nagusiak:
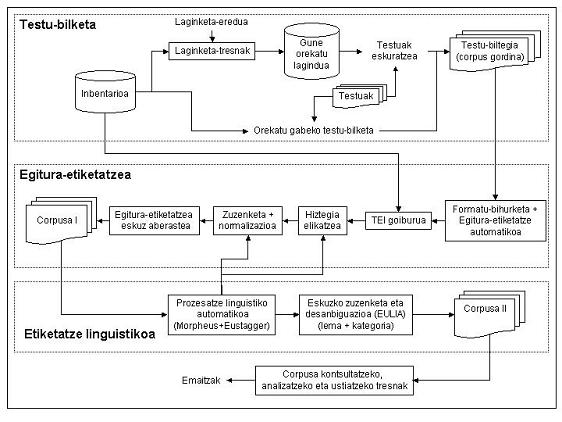
2. irudia. Corpusgintzaren diagrama.
5.1 Corpus gordina
TB moduluaren bidez kudeatzen da. Urrats honen helburua corpusean jasoko diren testuak hautatzeko, jasotzeko eta biltegiratzeko sistema diseinatzea eta inplementatzea da.
Horretarako, honakoak egin ditugu:
- Corpusean sartzeko hautagai diren obren inbentarioaren datu-basea
- Corpusean sartuko diren testu-laginak hautatzeko laginketa-tresnak. Corpus-diseinuan erabakitzen den laginketa-eredua modu automatikoan gauzatzeko tresna bat diseinatu eta inplementatu da. Tresna horren bidez, inbentarioan zehaztutako populaziotik lagin batzuk hautatzen dira, laginketa-ereduan ezarritako irizpideak automatikoki erabiliz
- Corpusean sartuko diren testu-laginen biltegi egituratua. Laginketan hautatutako testu-laginak
(testuak edo testu-zatiak), horien jabe edo hornitzaileengandik jasotakoan, biltegi egituratu batean gordetzen dira.
Biltegi hori diseinatu eta inplementatzean, honakoak hartu dira kontuan:
- Testu-lagina eskuratzeko bidea (dokumentu elektronikoa, OCRz digitalizatu eta ezagututako dokumentu inprimatua, tekleatutako dokumentua)
- Dokumentu elektronikoen kasuan, onartuko diren jatorrizko formatuak (.txt, .doc., .rtf, .html, .xml, .pdf, .qk...)
- Corpusean testu-lagin bakoitzari buruz etiketatuko den informazioa (metadatuak: izenburua, egilea, urtea,
etab.); informazio hori zein izango den diseinuan erabakitzen da, eta inbentariotik eta laginketa-eredutik sortzen da.
Hurrengo urrats batean, testu-laginaren
<teiHeader>-en kodetzen da, egitura-etiketatzearen aurretik edo ondoren
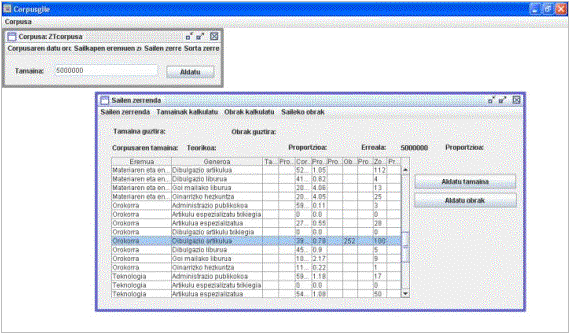
3. irudia. Inbentarioa sailka (geruzak).
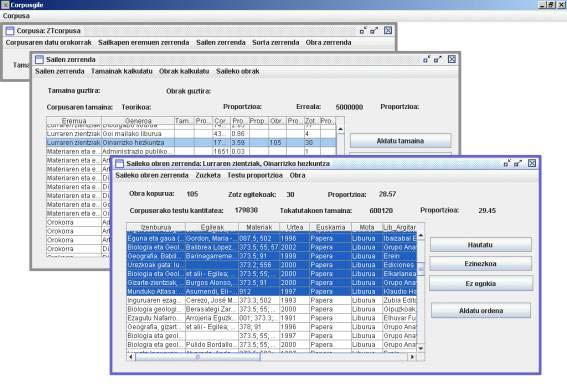
4. irudia. TB modulua: sail baten laginketaren emaitza (corpuseratzeko obrak nabarmenduta daude).
Testuak biltzeko hiru bide aipatu ohi dira: a) testua formatu elektronikoan jasotzea; b) testua eskaneatzea; eta c) testua eskuz idaztea ordenagailuan. Esan gabe doa, a) bidea da erosoena eta fidagarriena. Testuak formatu horretan jaso ahal izateko, argitaratzaileengana jo dugu. Horretarako, corpusaren helburua, erabilera eta testuak corpuseratzeko baldintzak zehazten dituen hitzarmena sinatzea proposatu zaie hornitzaileei. Zenbaitetan ordea, ezin izan da testua formatu elektronikoan eskuratu, eta eskaner bidez digitalizatu behar izan dugu.
Formatu elektronikoan jasotzen dugunean, jatorrizko dokumentuaren formatu hauek onartu ditugu: .html, .xml, .doc, .rtf, .txt, .pdf, .qk. Horietako formatu batzuek arazoak sortzen dituzte formatu-bihurketa automatikoa egiteko, eta bihurtu ondoren egiaztatu egin behar da dokumentuaren egitura eta formatu-ezaugarriak behar bezala eraman direla formatu berrira, karaktere-kodeketa zuzena dela eta ez duela aldatu jatorrizko karaktereen bistaratzea, lerro-amaierako marrak ez direla bihurtu hitz-barneko marra... Azken hori gertatu ohi da, adibidez, QuarkXpress-etik sortutako PDF dokumentuak HTML formatura aldatzean. Marra horiek guztiak berraztertu egin behar izan ditugu, eta, horretarako, ezagutza linguistikoa erabili dugu (funtsean, hau hartzen da kontuan txertatutako marra ebaluatzeko eta erdiautomatikoki prozesatzeko: etiketatzaile linguistikoak marra berriak banantzen dituen hitz-zatiak ezagutzen dituen, bakarra ezagutzen duen, eta abar).
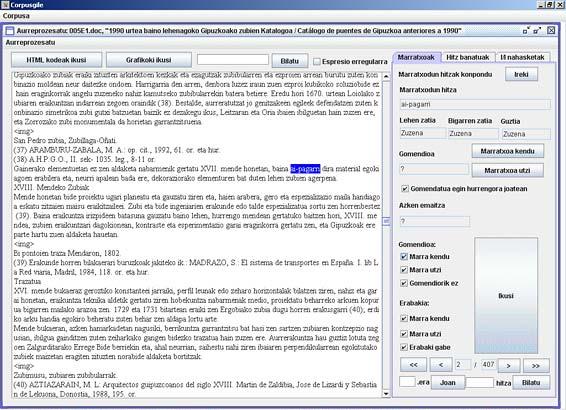
5. irudia. QuarkXpress-etik PDFra aldatutako dokumentuetan txertatzen diren hitz-barneko marrak ebaluatzeko eta zuzentzeko interfazea.
Bestetik, formatua bihurtzean jatorrizko formatu-ezaugarri batzuk gordetzea eta automatikoki prozesatzea interesatzen zaigu. Adibidez, egitura etiketatzean ikusiko dugu letra-estiloa (etzana, lodia...) atxikitzea interesgarria dela; beste hainbeste testuaren egiturari buruzko informazioa ematen duten estiloez (esaterako, Word-en erabiltzen diren 'atalburua', 'buletdun zerrenda', eta abar).
Horregatik, formatu-bihurketa batzuk egiteko berariazko bihurtzaileak programatu ditugu, .doc, rtf eta .html dokumentuak TEI bateragarriak diren .xml dokumentu bihurtzeko, hain zuzen ere.
Hasierara5.2 Etiketatzea
Corpusak kodetzeko eta etiketatzeko proposatu diren ereduen eta formatuen artean, TEI eredua eta XML teknologia hautatu ditugu. TEI (Text Encoding Initiative) nazioarteko estandar bat da, testu elektronikoak kodetzeko eta trukatzeko orientabideak proposatzen dituena (Arriola et al. 1997: 6). Gure etiketatze-eredua koherentea da TEI P4ren orientabideekin, orokorrekin zein hizkuntza-corpusetarako emandako orientabide bereziekin (23. atala; http://www.tei-c.org/P4X/CC.html).
5.2.1 Egitura-etiketatzea
TEIk aukera ugari eskaintzen ditu testuak etiketatzeko. ZT corpusean, testuen egitura eta formatu-ezaugarri zenbait markatzea erabaki dugu. Horiez gain, analisi linguistikoaren emaitzak hobetze aldera, zuzenketak eta aldaera ez-estandarrak etiketatzeko aukera ere baliatzen da.
5.2.1.1 Egitura-elementuak
<text>: obra bat edo obra baten laginak hartzen ditu bere baitan<body>: obra baten gorputza edo testua bera 2<div>: testuaren atal bakoitza hartzen du; maila atributuaren bidez,<div>-en arteko habiatzea adierazten da 3<head>: atalburua<p>: paragrafoa<table>,<row>,<cell>: taula, errenkada, gelaxka<list>,<item>: zerrenda, zerrenda-elementua<note>: oin-oharra
Bestetik, TEIren DTDari atributu bat erantsi diogu: orekatua. Horren bidez, corpus-gune orekatuan sartzen diren laginak markatzen dira. Horretara, obra baten testu osoa corpuseratu denean, gune orekatuko laginak bereiz etiketaturik daude, eta gune orekatuko laginak soilik edukiko lituzkeen azpicorpusa eratzea erraza da, beraz. TEI_XMLra bihurtu diren dokumentuetan, gune orekaturako pasarteak automatikoki hautatzeko eta markatzeko (paragrafoaren orekatua atributuan) programa egin da.
Testuaren joskeraren barnean irudi bat edo corpuseratzen ez den bestelako elementuren bat dagoenean (formulak, ekuazioak...),
<gap> elementu hutsaren bidez adierazten dugu gune horretan zerbait 'falta' dela.
5.2.1.2 Nabarmentzea eta aipuak
Letra-estiloaz (letra lodia, etzana, azpimarratua...), letra-tipoa aldatuz edo komatxoen bidez nabarmentzen diren zatiak
<hi> elementuaren bidez etiketatzen dira testua jatorrizko formatutik TEIra bihurtzen dugunean. Nabarmentze tipografiko
mota rend atributuaz markatzen da:
McDonnell-en NOTAR sisteman (<hi rend="italic">No Tail Rotor</hi> edo isats-errotorerik gabea hitzen
laburdura da), bihurdura-momentua...
<hi> elementua hitz baten barnean gertatzen denean, <seg> elementuaren bidez markatu da hitz osoa. Hori
garrantzitsua da etiketatze linguistikoa egiten denean, hitz osoa token bakartzat prozesatu ahal izateko. Esaterako,
metahizkuntza erabiltzen denean, maiz hitz hutsa letra etzanez idazten da, eta kasu-atzizkia letra arruntez, marraz loturik
zein marrarik gabe erantsita: " ingurumen-en aldeko erabakia", edo " garunen erabilera
testu teknikoetan". Horrelakoak honela etiketatu dira:
<seg><hi>ingurumen<hi>-en<seg>
<seg><hi>garun<hi>en<seg>
Horretara, etiketatze linguistikoa egitean, etiketak iragazi eta ingurumenen eta garunen tokenak doaz analizatzera.
Hurrengo urrats batean, <hi> elementuak eskuz aztertzen dira, eta honako balio hauetakoren batez ordezkatzen dugu:
<foreign>: testuko hizkuntzakoa ez den hitza edo pasartea<emph>: enfasi linguistiko edo erretorikoa<distinct>: linguistikoki berezia den hitz edo pasartea<q>: aipua; elkarrizketak ere elementu honen bidez etiketatzen dira; type atributuaren bidez bereizten dira galderak (type="answer") eta erantzunak (type="answer")<soCalled>: idazleak adiera berezia ematen dion (edo eman ohi zaion) hitz edo pasartea 4<term>: terminoa<gloss>: terminoaren azalpena edo definizioa<mentioned>: metahizkuntza<name>: izen bereziak (atributuak: pertsona, lekua, erakundea, objektua, artelana, produktua...)
Batzuetan, TEIk aurreikusi bezala, <hi > elementua bere horretan utzi da, aurreko funtzioetako bat esleitzerik izan ez
dugunean. Elementu horietako batzuetan, lang atributua (hizkuntza) zehaztu da: <q>, <term>, <soCalled>,
<mentioned>, <name>. 5
Aurreko adibidea honela agertzen da eskuz desanbiguatu ondoren:
McDonnell-en NOTAR sisteman (<term cert="ziurra" lang="en" rend="italic"
resp="hizking21">No Tail Rotor</term> edo isats-errotorerik gabea hitzen laburdura da),
bihurdura-momentua...
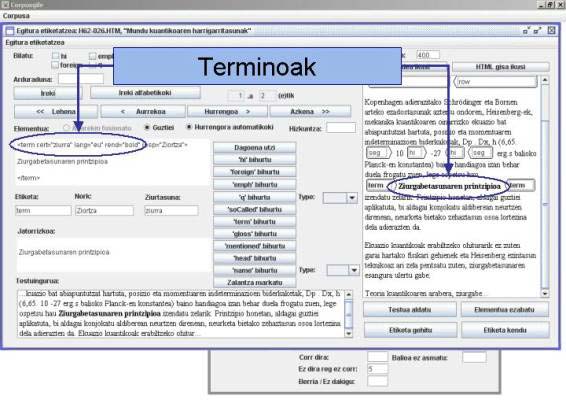
6. irudia. EE modulua: nabarmentzeen lanketa.
5.2.1.3 Zuzenketak, aldaketak
Etiketatze linguistikoen emaitzak hobetze aldera, zuzenketak eta aldaera ez-estandarrak etiketatzeko lana ere egiten dugu urrats honetan. TEI ereduak akats tipografikoak eta testu-hitz ez-estandarrak markatzeko eta, aldi berean, dagokion forma zuzenarekin eta aldaera estandarrekin erlazionatzeko aukera ematen du, hurrenez hurren.
Bi eratara marka daitezke: a) testu-hitza aldatu gabe, forma zuzendua edo aldaera estandarra atributuan markatzea; b) testuan forma zuzendua edo estandarra jartzea, eta jatorrizko testu-hitza, atributuan. Bigarren aukera hobetsi dugu, etiketatze linguistikorako erosoagoa delako.
- Akats tipografikoak:
<corr>elementua (jatorrizko testu-hitza:sicatributuaren balioa) - Aldaera estandarrak:
<reg>elementua (jatorrizko testu-hitza:origatributuaren balioa)
Adibidez:
<corr cert="ziurra" resp="hizking21" sic="baztuk">batzuk</corr>
<reg cert="ziurra" resp="hizking21" orig="zientzilari">zientzialari</reg>
Eustagger etiketatzaileak <corr> edo <reg> proposamenak automatikoki markatzen ditu testuan, eta gero horiek
denak eskuz aztertzen dira, balioesteko edo behar diren aldaketak egiteko (eskuz landutako corpus-atalean, noski).
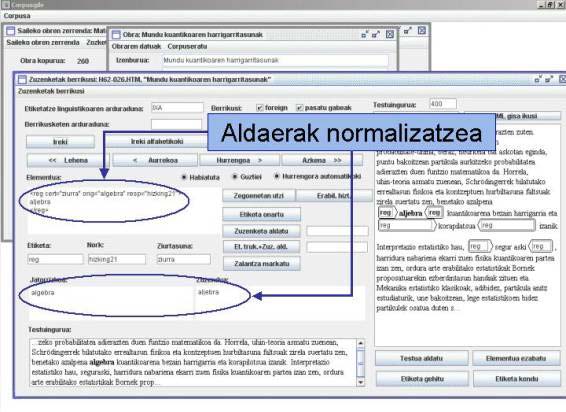
7. irudia. EE modulua: aldaera ez-estandarren normalizazioa.
Bestetik, TEIren DTDan, orekatua atributua erantsi diogu <p> elementuari. Horren bidez, corpus-gune orekatuan
sartzen diren laginen paragrafoak markatzen dira.
Azkenik, corpuseko obra bakoitzaren metadatuak obraren goiburuan (<teiHeader> elementuan) bildu ditugu (ISBN
zenbakia, izenburua, egilea, argitaratze-urtea, argitaletxea, eremua, generoa...). Metadatu horiek inbentarioaren DBtik
zuzenean ekartzen dira goiburura.
5.2.2 Etiketatze linguistikoa
Corpusa baliabide linguistikoa izango bada, ezinbestekoa da linguistikoki prozesatzea eta etiketatzea, alegia, corpuseko hitzak informazio linguistikoz aberastea. Hitzen informazio linguistikoa lortzeko, IXA taldearen hainbat tresna linguistiko erabili dira.
5.2.2.1 Urratsak
Hurrengo irudian dago ikusgai testuei ezartzen zaien prozesatze linguistikoaren eskema:
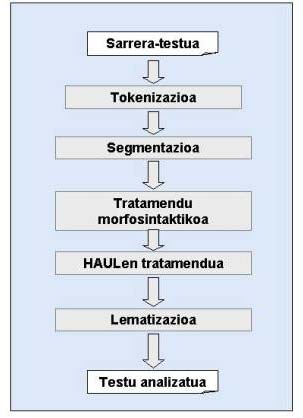
8. irudia. Prozesatze linguistikoaren oinarrizko eskema.
Labur esanda, honako eragiketa hauek egin dira testuon gainean:
- Tokenizazioa: testua token edo analisi-unitatetan bereizi, puntuazio-ikur, maiuskula-minuskula, ezaugarri ortotipografiko eta abarren tratamendua eginez
- Segmentazio morfologikoa: tokenak morfematan zatikatu, eta morfema bakoitzari dagozkion ezaugarriak esleitu. Prozesu honetan azaltzen da, estreinakoz, anbiguotasunaren arazoa, hitz-forma bat morfologikoki modu desberdinetan segmentatu ahal izango baita, eta, ondorioz, interpretazio bat baino gehiago izango dugu (kontuan hartu behar da segmentazioa testuingurua aintzat hartu gabe egiten dela, automatikoki)
- Analisi morfosintaktikoa: segmentazioaren emaitzatik abiatuz, hitz-formari dagokion lema osatu behar da (eratorpenaren kasuan, adib., oinarriari dagokiona aurrizki-atzizki lexikalekin elkartuz), eta forma osoari dagokion informazioa "goratzen" da morfema osagaien informaziotik (kasua, numero-mugatasunak, adib.)
- Hitz anitzeko unitateen tratamendua: hitz-forma solteen analisitik haratago, lexikalki unitatetzat har daitezkeen adierazpenak eta bestelako batzuk (entitate-izenak, data- eta zenbaki-adierazpenak, eta abar) ezagutzen dira fase honetan
- Lematizazioa: prozesu honetan, bi aspektu bereizi behar dira: (1) geroko analisi-urratsetan (sintaxian, batik bat) pertinentea litzatekeen informazioa bereiztea: lema, kategoria-azpikategoriak, hitz-formaren kasua, numeroa eta mugatasuna, pertsona(k) adizkietan, funtzio sintaktikoa, erlazioa, eta abar; (2) desanbiguazioa, hots, hitz-formari egoki dagokion interpretazioa zuzentzat markatzea (okerrak baztertuz), testuinguruari erreparatuz. Desanbiguazioa hizkuntza-ezagutzan oinarritua izango da (murriztapen-gramatika bat baliatuko da horretarako), alde batetik, eta estatistikoa, bestetik (ikaste automatikoko teknikak erabiliz, aldez aurretik eskuz desanbiguatutako corpus batean oinarrituz)
Lematizazioan aipatutako desanbiguatze hori automatikoa da (ez % 100 zuzena, beraz), eta horren emaitza da corpuseko atal irekian geratu dena. Gune orekatuan, ordea, eskuz berrikusi dira emaitzak, eta, prozesua burututakoan, gune hori anbiguotasunik gabe eta erabat zuzen lematizatua geratu da. Eskuzko berrikuste hori Eulia izeneko tresnaz baliatuz egiten da.
5.2.2.2 Baliabide lexikalak eta lematizazio-irizpideak
Prozesu hauetan guztietan erabiltzen den informazio lexikala EDBL datu-base lexikaletik dator ( http://ixa2.si.ehu.es/edbl/). EDBL lexiko-biltegi iraunkorra da, eta aparteko prozesu baten bitartez gobernatzen da. EDBLk euskara batuko lexiko orokorra islatzea du helburu, eta biltzen dituen hizkuntza-unitateak hiru espezializazio nagusitan sailkatuta daude: a) hizkuntza-unitate beregainak (hiztegi-sarrera direnak) eta morfema ez-independenteak; b) hizkuntza-unitate bakunak eta hitz anitzekoak (edo HAULak); eta c) unitate estandarrak eta ez-estandarrak (horien artean ere, bereizi egiten da bi unitateak elkarren aldaera diren ala ez).
Corpusa lematizatzeari begira, garrantzi nabaria du aldaera estandar eta ez-estandarren tratamenduak. Esan gabe doa, elkarren aldaera ez diren hitzek lema bereiziak dituzte, bata bestearen forma hobetsi edo estandarra izanagatik ere. Esaterako, Euskaltzaindiaren Hiztegi Batuan (eta beraz, EDBLn), "memoria 1 h. oroimen. 2 h. oroitzapen" ageri bada ere, argi dago memoria hitzaren agerraldien lema memoria dela, zein ere den memoria hitzaren estandartasun-maila (alde batera utzita Hiztegi Batuaren erabakiak ez duela kontuan hartu informatika-alorreko erabilera). Baina jarduera/iharduera, elkarzut/elkartzut, immunitate/inmunitate eta beste hainbat aldaera-kasuak dira. EDBLk badu aldaerei buruzko informazioa, eta, beraz, Eustagger-ek erabiltzen du informazio hori aldaera ez-estandarren testu-formei lematzat aldaera estandarra esleitzeko. Beraz, ZT corpusaren kontsulta-interfazean jarduera, elkarzut edo immune lemak eskatuz gero, iharduera, elkartzut eta inmune-ren agerraldiak ere bistaratuko dira.
Gainera, EDBLn zehaztuta ez dauden aldaera-kasu sistematiko batzuk ere lema bakarrera ekartzeko ahalmena badu Eustagger-ek: esaterako, aldaera fonologiko bakun direnak, hala nola -o/-u amaierak, tz/tx/ts aldaerak eta abar. Esaterako, EDBLn kartutxo dago, baina ez kartutxu; hala ere, Eustagger-ek kartutxu aldaeraren agerraldietarako kartutxo lema estandarra proposatzen du, arau fonologiko bakar bat aplikatuz hel daitekeelako kartutxu-tik kartutxo-ra.
Esan bezala, EDBLren asmoa lexiko orokorra jasotzea da, eta bistan da corpus berezi edo espezializatu batean erabiltzerakoan, komenigarria dela berariazko lexikoaz aberastea. Horregatik, etiketatze linguistikoan emaitzen doitasuna handitzeko asmoz, EDBLko lexikoari hiztegi edo 'lexikoi osagarri' partikular bat gehitu diogu. Hiztegi horretan, hizkuntza arruntean erabiltzen ez diren (hots, EDBLn ez dauden) hainbat termino zientifiko-tekniko gehitu dira. Horretara, hitz edo termino horien agerraldiak lematizatzen/etiketatzen direnean, sistemak zuzenean lematizatuko ditu, ez du beste lema-aukerarik aztertuko (teknikoki hitz eginda, ez da saiatuko lexikorik gabeko lematizazioa egiten, alegia). Hiztegi hori osatzeko, bi iturri erabili dira:
- Elhuyarren hiztegigintzako datu-basea (ElhDB): EDBLrekin erkatu da, hor ez dauden lemak lexikoi osagarrian sartzeko edo, batzuetan, terminoak orokor samarrak zirenean, EDBL bera aberasteko
- ZT corpusa bera: corpusaren erabilerari dagokionean, aurreprozesatze bat egin da EDBL+ElhDB baliabideen bidez ezagutzen ez diren hitzak detektatu eta Eustagger-ek proposatzen duen lemaren maiztasunaren arabera sailkatzeko. Maiztasun handieneko proposamenak aztertu eta, egokitzat hartu direnean, lexikoi osagarrian barneratu dira
Bi lan horiek etiketatze linguistikoaren beraren aurretik egiten dira, egitura-etiketatzearekin batera. Bigarren eginkizunerako, gainera, programa eta erabiltzaile-interfaze berezia garatu dira (Corpusgile- ren EE moduluan integratu da, zuzenketak eta aldaera ez-estandarrak etiketatzeko egitekoen aurretik).
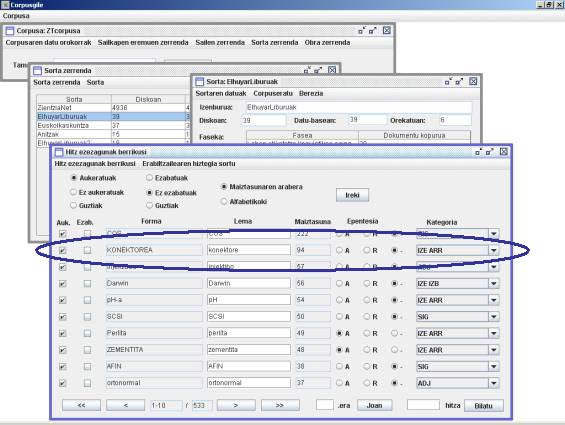
9. irudia. ZT corpusaren lexikoi osagarria elikatzeko lan-interfazea.
Nolanahi ere, EDBLn zehaztuta ez dauden aldaeren arteko estandartasun-erlazioak edo arau fonologiko baten bidez EDBLko sarrera estandar batekin ezin erlaziona daitezkeen aldaerak direla eta, ez da aldaera estandarrik esleitu, ez automatikoki prozesatzean ez eskuz zuzentzean ere. Adibidez, EDBLn ez protista ez protisto daude. Beraz, corpuseko protisto eta protista-ren agerraldiak zein bere lemarekin etiketatu dira. Azken batean, horietako kasu gehienetan, corpuseko datuak aztertuz ebatzi behar litzateke aldaeron estandartasuna, corpusaren helburua bera baita horretarako datuak eskaintzea. Erabaki hori aurreratzea litzateke corpusa eratzen duen lantaldeak etiketatze-lana hastean, hau da, erabilera-datuak oraindik lortu ez direnean, horrelakoen agerraldiak aldaera bakarraren pean lematizatzea. Corpusa aztertzen dutenen egitekoa da hori, hitz lauz esanda.
Hasierara5.2.2.3 Informazio linguistikoa
Etiketatze linguistikoaren amaieran, corpuseko hitz orok zenbait informazio linguistiko dauka erantsita, hala nola:
- Hitzaren lema eta kategoria lexikala (% 100 zuzen, eskuz desanbiguatutako atalean, eta automatikoki esleitutakoa, gainerakoan)
- Hitzak duen kasua eta betetzen duen funtzio sintaktikoa (automatikoki esleituak)
- Hitz anitzeko unitateen kasuan, unitate hauen egitura ere esplizituki errepresentatuko da, ezagutu direnen kasuan, jakina (EDBLn ziurtzat jotzen diren eta testuan etenik gabe agertu ohi direnak)
Bestetik, esan beharra dago marraz lotutako izen-izen elkarteak ere lematzat etiketatu direla: mahai-inguru, haize-energia...
Dena den, hitz anitzeko unitateen eta aipatutako hitz-elkarteen osagaien informazioa ere gorde da etiketatze linguistikoan, eta erabiltzaileak aukera dauka bilaketa osagai horietan egiteko. Aukera hori interesgarria da izen bat hitz-elkarteetan zein izenekin elkartzen den aztertu nahi badugu; izan ere, izen-elkarteak marraz lotuta zein zuriune batez bereizita idatz daitezke euskaraz (hitz bakarrean idazten direnak aparte utzita), eta bietara agertzen dira testuetan. Osagaietan bilatzen ez badugu, adibidez, haize-energia ez da agertuko haize lemaren agerraldiak eskatzen ditugunean, eta eskatutakoaren ondoko izenen maiztasunak jakin nahi baditugu, haize energia modukoak kontuan hartuko dira, baina ez haize-energia modukoak. Aztertu nahi dugun fenomenoaren ikuspegitik (hau da, hitz-konbinazioen azterketaren ikuspegitik), marra ez da esanguratsua, eta interesatzen zaiguna da bi idazkera-motak kontuan hartuko dituen bilaketa-sistema. Horretarako, osagaietan bilatu besterik ez dugu.
5.2.2.4 Etiketatze- edo anotazio-eredua
Testuak linguistikoki etiketatzeko (anotatzeko), bi hurbilpen nagusi jarraitu ohi dira historikoki. Batean, informazio
linguistikoa jatorrizko corpusean txertatzen da, hitzekin batera, orain arte ikusi ditugun etiketak bezala (<text>,
<body>, <hi>, eta abar) erabiliz. Bestean, berriz, informazio linguistikoa hitzak dauden dokumentu nagusietatik at
gordetzen da, horretarako berariaz sortutako dokumentuetan, alegia. Hitzak dagokien informazio linguistikoarekin lotzeko,
bestalde, estekak erabiltzen dira. Azken hurbilpen horri anotazio banatua (stand-off annotation edo markup)
esaten zaio, eta horixe erabili da gurean corpusa linguistikoki etiketatzeko (Aldezabal et al., 2002).
Informazio linguistikoaren konplexutasuna kontuan harturik, hurbilpen honek abantaila hauek eskaintzen dizkigu, besteak beste:
- Informazio teilakatua adierazteko aukera ematen du, eta, ondorioz, analisi linguistiko anbiguoak adierazteko.
- Informazio linguistikoa hainbat mailatan edo geruzatan antola daiteke, eta geruza bakoitza independentea izan daiteke besteekiko. Geruza batean aldaketak egin behar badira, aldaketek eragin txikia izango dute gainerako geruzetan. Beraz, anotazioaren hedagarritasuna errazten du, corpusaren gainean informazio linguistiko osagarria txerta baitaiteke, dagoen informazioaren gainean oinarriturik.
- HAULen osaera errepresentatzeko modu egokia eskaintzen du, baita hitz anitzeko unitate horiek testuan etenda gertatzen direnean ere.
- Desanbiguatze-egoera (eskuzkoa, automatikoa) zein den adierazteko era egokia eskaintzen du.
- Diagraman (10. irudia), anotazio banatuaren oinarrian dagoen eskema irudikatu da. Funtsean, hiru elementuk hartzen dute parte guk amarauna esaten diogun anotazio-arkitektura honetan:
- Aingurak: testu-elementuak edo, oro har, aurreko prozesuek sortutako interpretazioak izan daitezke anotazioen jomuga edo helduleku.
- Informazio linguistikoa: prozesu linguistikoek eraikitako analisi-biltegiak, ezaugarri-egiturak (feature structures) erabiliz errepresentatuak.
- Estekak: aurreko biak lotzen dituzten elementuak, hau da, aingura bat (testu-hitz edo -zati bat, esate baterako) dagokion informazio linguistikoarekin (lematizazioaren emaitza, adibidez) estekatzen duen elementua.
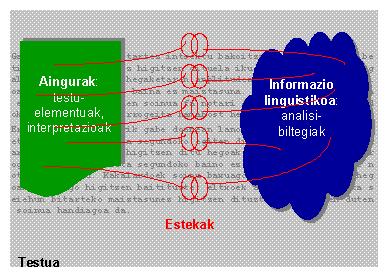
10. irudia. Anotazio banatua, eskematikoki.
Hiru elementu horiek, praktikan, elkarrekin lotutako hainbat XML dokumenturen bitartez gauzatzen dira, testu batek jasan dituen prozesu linguistikoen emaitzak (anotazioak) biltzen dituztenak. Beheko irudian (11. irudia) adibide konkretu bat ikus daiteke: Horrela, euliak hegan egitean igortzen duen soinua... esaldiaren lematizazioaren ondoren izango genukeen anotazio-amarauna dago bertan irudikatua, eskematikoki. Kasu honetan, bost dokumentuk osatzen dute amarauna: jatorrizko testua (egitura-etiketatzearen emaitza), tokenizazioaren emaitza (Testu tokenizatua, irudian), lematizazioen bilduma (Lematizazioak), HAULen egitura errepresentatzen duena eta esteken dokumentua. Ikus daitekeenez, aingurak testu tokenizatuan eta HAULen egitura errepresentatzen duen dokumentuan aurki daitezke. HAULen egitura adierazteko, tokenen dokumentuko unitateen erakusleak erabiltzen dira, eta horrela errepresentatzen da, adibidez, hegan eta egitean tokenak lematizazio-unitate beraren osagai direla. Estekei erreparatuz gero, berriz, aise ohartuko gara interpretazio-anbiguotasuna nola errepresentatzen den (euliak formak bi lematizazio posible ditu: ergatibo singularra eta absolutibo plurala, eta, hortaz, bi estekak dute helduleku token horretan), eta baita desanbiguatze-egoera adierazten duen type atributuaren funtzioaz ere (Correct balioak adierazten du, desanbiguazioaren ondoren, interpretazio zuzena zein den). Azkenik, lematizazioen bilduma dugu informazio linguistikoaren atalean, non, ezaugarri-egitura batek errepresentatzen baitu hitz-forma desberdin bakoitzaren lematizazio-informazioa: forma bera, lema osatua eta goi-mailako zein morfemaz morfemako informazio morfologikoa (kasua, funtzio sintaktikoa eta abar).
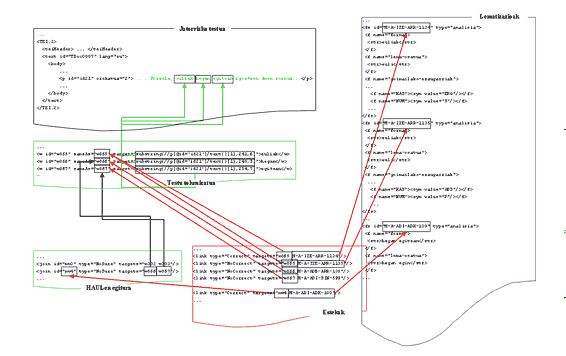
11. irudia. Etiketatze linguistikoa. Anotazio banatua: dokumentu-amarauna.
Etiketatze linguistiko automatikoa egindakoan, emaitzak eskuz lantzeko aukera dago. Lan hori corpusaren gune orekatua osatzen duten testuetan egiten dugu. Lan hori Corpusgile-ren EL moduluan egiten da, eta hurrengo atalean xeheago azalduko dugu.
Hasierara5.2.2.5 EL modulua
EL modulua corpusaren gainean etiketatutako informazio linguistikoa gainbegiratzeko, orrazteko eta desanbiguatzeko ingurunea dugu, eta giza erabiltzaileari zuzenduta dago. Modulu honen osagai nagusia Eulia izeneko tresna bat da, eta berorri esker linguistek zein etiketatzaileek aurreko urratsetan sortutako informazio linguistiko guztia aztertzeko aukera dute, eta, nahi izanez gero, informazioa gehitu, aldatu edo/eta zuzentzekoa (Artola et al., 2004)
Eulia-ren helburuak honako hauek dira:
- Analisi-tresnak modu integratu batez koordinatu, eta tresna horien emaitzak kudeatzeko laguntza eskaini.
- Hizkuntzalariari anotazioen adierazpidea eta konplexutasuna ezkutatu, bere lana modu atsegin batean egin ahal izan dezan.
Eulia honako prozesu hauetan erabiltzen da:
- Analisi-prozesu automatikoak, oro har: testu bat hautatu, eta berorren tokenizazioa, segmentazioa, analisi morfosintaktikoa, lematizazioa eta abar abiarazi eta egikaritu.
- Aldez aurretik prozesatutako testu baten analisi-emaitzak ikuskatu, eta berorien gaineko bilaketa oinarrizko nahiz konplexuak egin.
- Eskuzko desanbiguazioa: interpretazio bat baino gehiago daudenean zuzena markatu, akatsak zuzendu, interpretazio zuzenik ez dagoenean sortu, eta abar. Sistemak bermatzen du zuzenketak edo/eta analisi berriak TEI gidalerroen arabera egiten direla, hau da, sortzen diren ezaugarri-egiturak dagokien motaren arabera eratuta sortzen direla.
Eulia proiektuan erabiltzeko egokitu da, eta Corpusgile-n integratuta dago.
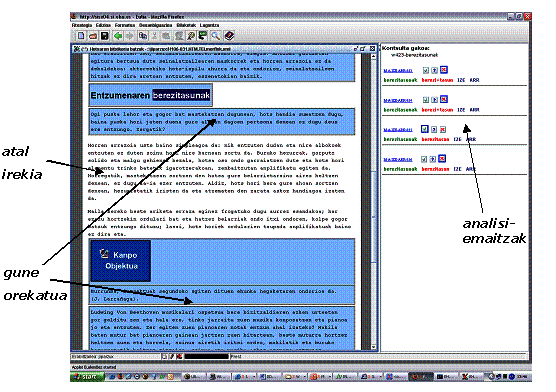
12. irudia. Eulia-ren lan-interfazea.
Irudian (12. irudia), Eulia-ren interfaze grafikoa ageri da. Irudiaren ezkerraldean Testu-leihoa dugu eta eskuinekoan Analisi-leihoa. Beheko aldean ohiko Egoera-barra ere ikus daiteke. Ikus ditzagun, bada, bi leiho nagusiak.
5.2.2.5.1 Testu-leihoa
Testu-leihoan, sarrera-testua (gure kasuan, egitura-etiketatzearen emaitza), tokenizazioaren emaitza eta HAULen fitxategia prozesatzearen ondorioz sortutako testu-egitura bistaratzen da. Irudian ikus daitekeenez, corpusaren gune orekatukoak diren paragrafoak nabarmenduta ageri dira eta atal irekikoak zuriz. Leiho honetan bi motatako osagaiak nahasten dira:
- Tokenizatzaileak ezagutu dituen zatiak: linguistikoki interesgarriak diren testu-zatiak dira, hau da, tokenak. Tokenei lotuta analisi linguistikoak egon daitezke.
- Tokenizaziotik at gelditu diren zatiak: multzo hau hutsuneek, lerro-jauziek eta abarrek osatzen dute; mota horretako osagaiek ez dute analisi linguistikorik.
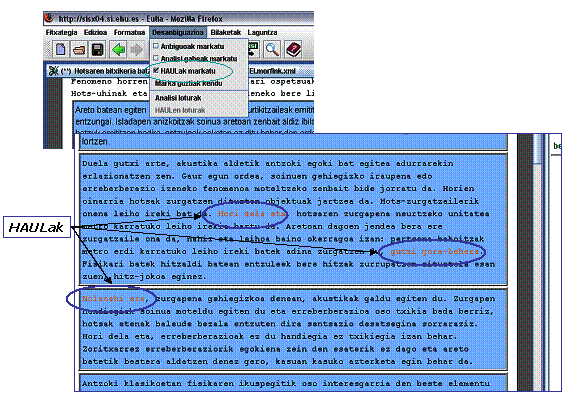
13. irudia. HAULak markaturik, Eulia-ren interfazeko testu-leihoan.
Itxurari dagokionez, ezin dira osagai horiek bereizi. Eulia-ren helburuetako bat jatorrizko testua idatzita dagoen modu berean erakustea da; beraz, tokenizaziotik at gelditu diren zatiak, linguistikoki interesgarriak izan ez arren, erakutsi egin behar dira.
Testu-leihoan token baten gainean klik egiten dugunean, horrekin erlazionatzen diren tokenen araberako ekintzak abiaraz daitezke. Hona hemen suerta daitezkeen kasuak:
- Klikatutako tokena ez da HAUL baten parte: kasu honetan, klikatutako tokena tokenizazio-fitxategian azaldutako testu-erreferentzien arabera markatzen da, eta bere analisi guztiak analisi-leihoan erakusten dira.
- Klikatutako tokena HAUL baten edo gehiagoren parte da: tokena eta dagokion HAUL bakoitza markatzen dira (erabiltzaileak hala nahi badu, noski: ikus 13. irudia), eta analisi-leihoan tokenaren analisiak eta markatutako HAULenak erakusten dira.
Interfazeak aukera ematen du, bada, testu-leihoko hitzen gainean klik egin eta dagokien informazioa ikuskatzeko. Horretaz gain, markak erabiltzen dira hitzak bereizteko: analisi anbiguoak dituztenak modu berezi batez bistaratzen dira, erabiltzaileak hautatutakoa(k) beste modu batez, eta abar. Marka hauen guztien itxura pertsonaliza daiteke erabiltzaile bakoitzarentzat.
5.2.2.5.2 Analisi-leihoa
Leiho honetan, testu-leihoan markatutako tokenekin erlazionatutako analisiak erakusten dira. Analisia erakusteko, zenbait estilo-orri definitu dira, erakutsi beharreko analisi-mota eta ikusi nahi den informazioaren xehetasun-maila kontuan izanik. Horri esker, amarauna osatzen duten XML dokumentuak ezkutuan gelditzen dira, eta erabiltzaileak modu gardenean ikus eta erabil dezake informazio linguistikoa. Irudiaren goiko aldean (14. irudia) ikus daitezke euliak hitz-formaren bi lematizazio posibleak zerrenda batean, non lehena zuzentzat markaturik ageri den (desanbiguazio automatikoaren ondorioz edo hizkuntzalariak analisi hori eskuz hautatu duelako). Beheko aldean, berriz, lematizazio horren xehetasunak ikus daitezke: informazio goratua eta morfemaz morfemako informazio xehatua.
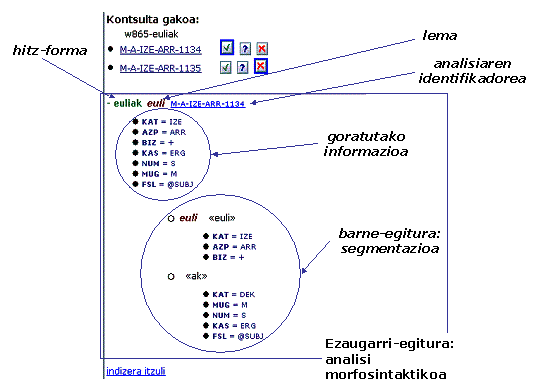
14. irudia. Eulia-ren interfazeko analisi-leihoa (xehetasuna).
Estilo-orriak horrela erabilita, leiho honek izan ditzakeen funtzionalitateak irekita gelditzen dira. Hemen erakusten den informazioa eta erabiltzaileekin duen harremana estilo-orri baten bidez defini daiteke. Erabilpen berezietarako, estilo-orri konplexuak defini daitezke, eta analisi-leihoan komandoak edo bilaketa berriak egiteko aukerak gehitu daitezke. Hau tresna indartsua da, eta, unean tratatzen den informazioaren arabera, interes gehien duten ekintzak eskain daitezke, modu adimentsuan.
Testu-leihoko dokumentu bakoitzeko, analisi-leiho bat dago; horretara, aktibo dagoen dokumentuaren arabera, analisi bat edo beste erakutsiko dugu.
Hasierara6 Ondorioak
Hizkuntza orok bezala, euskarak ere corpusak behar ditu; hizkuntzalariek, terminologoek, hizkuntza-teknologien ikertzaileek, hizkuntzaren estandarizazioaren ardura dutenek, hainbatek behar ditu corpusak, gaur egun hizkuntza aztertzeko ezinbesteko baliabide direlako. Zientzia eta Teknologiaren Corpusa-ren bidez, baliabide egoki eta ahaltsu bat eskaini nahi dugu espezialitate-alor horietan erabili den hizkuntza aztertzeko.
Euskara ez da hasiberria alor horietako testugintzan. 30 urte baino gehiago iragan dira zientzia eta teknologiako lehen testuak argitaratzen hasi zirenetik. Handik hona egin den bidearen zati bat baino ez du bere baitan hartuko ZT corpusak, 1990-2002 bitartekoa alegia, baina gure iritzia da aski datu-bilketa egokia izan daitekeela, batez ere kontuan hartzen badugu aurreko urteetako hizkuntza erabileraren 'heldutasuna' urte-bitarte horretan erdietsi bide duela euskarak, eta horretan eragin handia izan duela Euskaltzaindiaren araugintza berriak eta Hiztegi Batuak.
Baina corpusak berak ez ezik, horiek eratzeko teknologia ere behar dugu, corpusgintza-prozesua behar bezala bideratu eta kudeatzeko, eta hain handiak izaten diren kostuak gutxitzeko. Bestetik, corpusa eratzeko metodologia zehaztu eta ezarri dugu, corpusgintzan behar diren tresnak eta baliabideak moldatu edo garatu ditugu, eta prozesu osoa bere baitan hartzen duen aplikazio batean, Corpusgile-n, integratu.
Hori guztia egitean, oso izan dugu gogoan euskarak gaur egun premiazkoa duen erreferentzia-corpusa. Gure lanak egitasmo hori bideratzen eta gauzatzen lagun lezakeela uste dugu, batez ere garatu dugun metodologiari eta corpusgintza-tresnari esker, baina baita eratu dugun baliabidearen berrerabilgarritasunari esker ere.
Horiek dira, metodologia, tresna eta baliabidea, hain beharrean gauden alor honetara egin nahi ditugun ekarriak.
Hasierara7 Bibliografia
- ALEGRIA, I., ARETA, N., ARTOLA, X., DÍAZ DE ILARRAZA, A., EZEIZA, N., GURRUTXAGA, A., LETURIA, I., SAIZ, R., SOLOGAISTOA, A., SOROA, A. & VALVERDE, A. 2005. "Zientzia eta teknologiaren corpusa." In Mendebalde Kultur Alkartea, IX. Jardunaldiak: Euskera zientifiko-teknikoa. Bilbo. http://ixa.si.ehu.es/Ixa/Argitalpenak/Artikuluak/1113384045/publikoak/ZT_Corpusa_Mendebalde.pdf
- ALDEZABAL, I., ALEGRIA I., ANSA O., ARREGI X., ARTOLA X., DÍAZ DE ILARRAZA A., EZEIZA N., GOJENOLA K., HERNÁNDEZ G., MAYOR A., ORONOZ M. & SOROA A. 2002. Hizkuntza prozesatzeko tresnen integrazioa, SGML erabiliz. Barne-txostena. UPV/EHU/LSI/TR 2-2002
- ARRIOLA, J., ARTOLA, X., GOJENOLA, K., & SOROA, A. 1997 "TEI: testu-kodeketarako gidalerroak." In Ekaia: Euskal Herriko Unibertsitateko Zientzi eta Teknologi aldizkaria, 7. zenbakia. Udazkena.
- BACH, C., SAURÍ, R., VIVALDI, J. & CABRÉ, M.T. 1997. El corpus de l'IULA: descripció. Bartzelona: Universitat Pompeu Fabra. Institut universitari de Lingüística Aplicada
- BIBER, D., CONRAD, S. & REPPEN, R. 2000. Corpus Linguistics - Investigating Language Structure and Use.. Cambridge: Cambridge University Press.
- BIBER, D. 1993. "Representativeness in Corpus Design." In Literary & Linguistic Computing8. 243-257. orr.
- BOWKER, L, & PEARSON, 2002. J. Working with Specialized Language. A practical guide to using corpora. New York: Routledge
- LEECH, G. 2002 "The Importance of Reference Corpora." In Hizkuntza-corpusak. Oraina eta geroa. Donostia: UZEI. [on line] [kontsulta: 05-01-22] http://www.uzei.org/corpusajardunaldia/06_gleech.pdf
- MACMULLEN , W. J. 2002 Requirements Definition and Design Criteria for Test Corpora in Information Science. SILS Technical Report 2003-03 School of Information and Library Science University of North Carolina at Chapel Hill [on line] [kontsulta: 05-01-22] http://ils.unc.edu/ils/research/reports/TR-2003-03.pdf
- OIHARTZABAL , B. 2002. "Euskaltzaindiaren corpusez." In Hizkuntza-corpusak. Oraina eta geroa. Donostia: UZEI [on line] [kontsulta: 05-01-22] http://www.uzei.org/corpusajardunaldia/07_boihartzabal.ppt
- SINCLAIR, J, 1996. Preliminary Recommendations on Corpus Typology. EAGLES. [on line] [kontsulta: 05-01-22] http://www.ilc.cnr.it/EAGLES96/corpustyp/corpustyp.html
- URKIA, M. 2002. "XX. mendeko euskara-corpusa." In Hizkuntza-corpusak. Oraina eta geroa. Donostia: UZEI [on line] [kontsulta: 05-01-22] http://www.uzei.org/corpusajardunaldia/03_murkia.pdf
- Text Encoding Initiative. The XML version of the TEI Guidelines. [on line] [kontsulta: 05-01-22] http://www.tei-c.org/P4X/
- VIVALDI, J., DE YZAGUIRRE, Ll., SOLÉ, X.. &CABRÉ, M.T. 1996. Marcatge Estructural i Morfosintàctic del Corpus Tècnic amb l'estàndar SGML. Bartzelona: Universitat Pompeu Fabra. Institut universitari de Lingüística Aplicada. Serie Informes, 1
1. 'Bestelako gaiak' eremuan, zientzia eta teknologiaren alorrean sartu ohi ez diren baina mugakotzat jo litezkeen zenbait alorretako testuak sartu ditugu. Ez da batere samurra horrelakoetan erabaki argi eta zalantzagabea hartzea, eta irizpideak zehaztea ere zaila da.
2. <body> elementuaren aurretik eta ondoren antola daitezkeen <front> eta
<back> elementuak ez ditugu erabili; elementu
horietan, azala, aurkibideak, eskaintzak, bibliografia, aurkibide
analitikoa, eta abar antolatzen dira. Elementu bereizietan etiketatzeko
lana eskuz egin behar izaten da, eta, gainera, batzuek ez dute interes
linguistiko berezirik (bibliografiak, adibidez). Horregatik,
corpuseratu direnak <body> elementuaren barnean antolatu dira.
3. <div> elementua automatikoki etiketa daitekeenean baino ez da gauzatu; jatorrizko
hainbat dokumentutan, testuak ez dakar egituratze-informaziorik, eta horrelakoetan ez da <div> elementua erabili
4. TEIn honela definitzen da <soCalled> elementua: "Contains a word or phrase
for which the author or narrator indicates a disclaiming of responsibility, for example by the use of scare quotes or italics.
Common examples include the 'scare' quotes often found in newspaper headlines and advertising copy, where the effect is to cast
doubts on the veracity of an assertion. (...) The same element should be used to mark a variety of special ironic usages."
5. Beraz, <foreign> elementua testuko hizkuntzakoa ez den eta beste elementu horietako bat esleitzerik ez
dagoen hitz edo pasartea markatzeko mugatu dugu