Zientzia eta Teknologiaren Corpusa
Gune orekatuaren tamaina (n)
Hizkuntza-erakusgarriak biltzen dituzten baliabideen adierazgarritasunean eragin handienekoa duen faktorea da tamaina. Gehienetan, tamaina hitz-kopuruarekin lotzen da, besterik gabe, baina honakoak ere kontuan hartzekoak dira: testu-tipologiaren araberako mota (kategoria) bakoitzeko testu-kopurua, testu bakoitzetik hartzen den lagin-kopurua eta lagin bakoitzaren hitz-kopurua (Kennedy, 66; Grönqvist et al.).
Corpus-diseinuan hutsik egin gabe aipatzen da corpusaren tamainaren 'default value' delakoa 'handia' dela (Sinclair, 6). Arrazoia da lagin 'asko' jaso behar direla hizkuntzaren dibertsitatea eta aldakortasuna jasotzeko eta emaitza estatistiko esanguratsuak lortu ahal izateko. 'Handi' esateak ez du gauza handirik adierazten, ordea. Gainera, corpusen tamainan erabakigarri izan diren faktoreak, adierazgarritasuna lortzeko irizpide objektiboak baino gehiago, corpusak eratzeko unean-unean izan diren baliabide edota teknologien menpekoak izan dira gehienetan. Egia da ez dela lan erraza irizpideok objektiboki zehaztea. Gaur egun, teknologiak testuak bildu eta corpusak eratzeko eskaintzen dituen baliabideak izugarri garatu dira, eta tamaina gero eta arazo txikiagoa da. Nabarmendu egin da, horren ondorioz, tamaina jakin batetik aurrera corpusa handitzearen errentagarritasuna gutxituz doala (gero eta hizkuntza-fenomeno berri gutxiago sartzen dira corpusean). Konpromiso bat bilatu behar da, beraz, tamaina handitzeko egiten den ahaleginaren eta lortzen den etekinaren artean. Horrez gain, aipatu beharrekoa da tamaina handiagoa izateak, besterik gabe, ez duela esan nahi corpusa adierazgarriagoa denik (Bowker et al., 45). Aditu batzuek diotenez, corpusak behar bezain handia eta ahal bezain txikia izan behar luke (MacMullen, 14) (horretarako gakoa 'oreka' litzateke, inondik ere).
Zenbat hitzeko corpusa behar da alor jakin bateko hizkuntza-erabileraren testu-lagin adierazgarria eta ondorio fidagarriak ateratzeko modukoa lortzeko? Lehen begiratu batean, zentzuzkoa da pentsatzea erreferentzia-corpus orokorretan baino hitz-kopuru txikiagoa behar dela gutxieneko adierazgarritasuna bermatzeko. Dimentsio apalagoa behar dela, alegia.
Gaur egun helburu orokorretarako diseinatzen diren corpusen tamaina estandar moduko bat 100 milioi hitzekoa dela onar liteke. Euskarazko corpusetan, askoz ere tamaina txikiagoetara baino ez gara heldu (OEH-ko testu-corpusa ≅ 5,5 milioi testu-hitz; XX. mendeko Euskararen Corpus Estatistikoa≅ 4,5; Ereduzko Prosa gaur ≅ 19,8).
ZT corpusaren tamaina erabakitzeko datu nolabait 'objektiboagoetan' oinarritu ahal izateko, corpusaren tamainaren eta lema-kopuruaren arteko erlazioa landu dugu. Horretarako, Yang eta al.en lanean oinarritu gara. Horien arabera, lema-kopurua/corpus-tamaina erlazioari gehien hurbiltzen zaion funtzioa y = f(x) = αxβ da (x = corpusaren tamaina, y = lema-kopurua), eta errore karratu minimoen metodoa erabiltzen dute datu errealei gehien hurbiltzen zaizkien α eta β parametroak kalkulatzeko. Metodo hori euskarazko corpusetara aplikatzeko, azterketa bat egin dugu, bi corpus hauek hartuta: Pentsamendu Unibertsalaren Klasikoak bilduma (6.500.000 hitz) eta Zientzia.net-eko Elhuyar Zientzia eta Teknika aldizkaria (2.400.000 hitz). Lehenengoa osatzeko testuak Internetetik lortu ditugu (www.klasikoak.com). Uste dugu eratzen ari garen ZT corpusaren ezaugarriak eta bi corpus horien ezaugarriak ez direla oso desberdinak izango tamaina/lema-kopurua alderdiari dagokionez: Zientzia.net.eko testuak espezializatuak dira eremu aldetik, nahiz eta erregistroa dibulgazio-maila den; Pentsamendu Unibertsalaren Klasikoak bilduma, berriz, erregistro jasokoa da, eremu aldetik zientzia eta teknologiakoa ez den arren (liburu gutxi dira alor horretakoak, zoritxarrez).
Horietako bakoitzean azpicorpusak osatu ditugu, bakoitza aurrekoa baino 100.000 hitz handiagoa, eta hainbat ezaugarriren bilakaera aztertu dugu: lema-kopurua, testu-hitz kopurua, izen-kopurua, adjektibo-kopurua, aditz-kopurua... Testua lematizatzeko, IXA taldearen Eustagger etiketatzailea erabili dugu. Lema-kopuruaren kalkulua egiteko, Eustagger lexikorik gabeko lematizazioan lortzen duen etekinaren estimazioa jakin behar da; lagin bat azterturik, asmatze-tasaren balioa kalkulatu da, eta hori erabili da lema-kopuruak ateratzeko.
| Corpusa | Analisi-mota | α | β |
|---|---|---|---|
| Pentsamendu Unibertsalaren Klasikoak | Izen bereziak kontuan harturik | 56,81 | 0,4472 |
| Izen bereziak kontuan hartu gabe | 55,25 | 0,4487 | |
| Zientzia.net | Izen bereziak kontuan harturik | 44,17 | 0,4741 |
| Izen bereziak kontuan hartu gabe | 42,31 | 0,4763 |
Horien irudikapena:
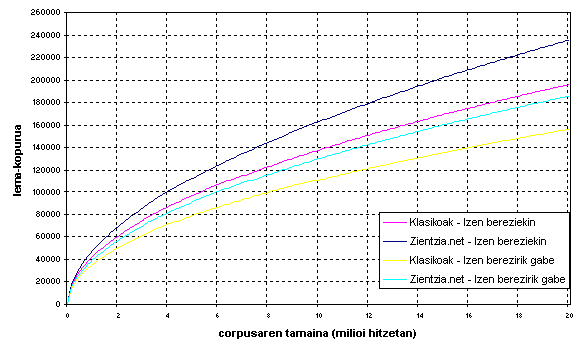
1. irudia. Corpusaren tamainaren eta lema-kopuruaren arteko erlazioa
Datu horiek ikusita, eta proiektuari eslei lekizkiokeen baliabideak kontuan harturik, corpusaren gune orekatua 5 milioi hitzekoa izatea erabaki dugu. Izen bereziak aparte utzita, 80.000-90.000 bitarteko lema-kopurua lortzea espero daiteke.
Bibliografia
- BOWKER, L. & PEARSON, J. 2002. Working with Specialized Language. A practical guide to using corpora. New York: Routledge.
- GRÖNQVIST, L. & HELGADÓTTIR, S. 2002. Literature review of representativeness of linguistic resources. GSLT course on Linguistic Resources.
- KENNEDY, G. 1998. An introduction to Corpus Linguistics. Londres: Longman. Studies in Language and Linguistics.
- MACMULLEN, W.J. 2002 Requirements Definition and Design Criteria for Test Corpora in Information Science. SILS Technical Report 2003-03 School of Information and Library Science University of North Carolina at Chapel Hill [on line] [kontsulta: 06-12-14] http://sils.unc.edu/research/publications/reports/TR-2003-03.pdf
- SINCLAIR, J. 1996. Preliminary Recommendations on Corpus Typology. EAGLES. [on line] [kontsulta: 05-01-22] http://www.ilc.cnr.it/EAGLES96/corpustyp/corpustyp.html
- YANG, D.H., CANTOS, P. & SONG, M. 2000. "An Algorithm for Predicting the Relationship between Lemmas and Corpus Size." In ETRI Journal, 22/2: 20-31 . [on line] [kontsulta: 05-01-22] http://etrij.etri.re.kr/Cyber/servlet/GetFile?fileid=SPF-1042453354988